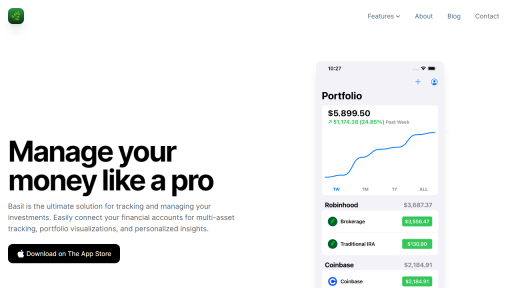
What is Synthetic Standard?
Synthetic Standard is an innovative tool designed to streamline the process of creating and managing synthetic data for various applications, including machine learning and data analysis. By generating high-quality synthetic datasets, the tool enables users to overcome the challenges posed by data scarcity, privacy concerns, and compliance issues associated with using real-world data. Synthetic Standard employs advanced algorithms that mimic real-world data distributions while ensuring that sensitive information remains protected. Users can customize the generated datasets to reflect specific characteristics needed for their projects, allowing for flexible and scalable data solutions. The tool is particularly beneficial for industries like finance, healthcare, and technology, where data privacy regulations can hinder data usage. By providing a safe environment for data experimentation, Synthetic Standard empowers organizations to foster innovation and improve their models’ accuracy without compromising user privacy.
Features
- Customizable Data Generation: Users can specify parameters and constraints to create datasets that closely resemble their real-world counterparts.
- Privacy-Preserving Algorithms: The tool utilizes advanced techniques to ensure that synthetic data does not expose any sensitive information from original datasets.
- Seamless Integration: Synthetic Standard easily integrates with popular data analysis tools and machine learning frameworks, allowing for a smooth workflow.
- High Data Fidelity: The generated datasets maintain high fidelity, ensuring they are statistically representative of the original data.
- Scalability: Users can generate datasets of varying sizes, accommodating projects ranging from small experiments to large-scale deployments.
Advantages
- Enhanced Data Privacy: Synthetic Standard mitigates the risks associated with data breaches and compliance violations by providing non-identifiable datasets.
- Cost-Effective Solution: Reduces the need for expensive data collection and management processes, saving organizations time and resources.
- Faster Model Development: By providing readily available synthetic data, teams can accelerate the training and testing of machine learning models.
- Improved Testing & Validation: Users can thoroughly test their algorithms using diverse synthetic datasets that cover various scenarios and edge cases.
- Facilitated Collaboration: Teams can share synthetic datasets without legal concerns, fostering collaboration across departments and organizations.
TL;DR
Synthetic Standard is a tool for generating customizable, privacy-preserving synthetic datasets that enhance data privacy and accelerate machine learning model development.
FAQs
What types of data can Synthetic Standard generate?
Synthetic Standard can generate various types of data, including numerical, categorical, and time-series data, tailored to your specific requirements.
Is the synthetic data generated by Synthetic Standard statistically valid?
Yes, the synthetic data generated maintains high statistical validity, ensuring it closely resembles the distribution of the original datasets.
Can I integrate Synthetic Standard with my existing tools?
Absolutely! Synthetic Standard seamlessly integrates with a variety of data analysis tools and machine learning frameworks to enhance your workflow.
How does Synthetic Standard ensure data privacy?
Synthetic Standard uses advanced algorithms to generate data that does not contain any identifiable information, ensuring compliance with data privacy regulations.
Is there a limit to the size of datasets I can generate?
No, there is no strict limit. You can generate datasets of varying sizes, from small samples for testing to large datasets for comprehensive analysis.